Associations With ActiveRecord
This post is based on the models I made for my demo API from the last post.
I want to make an app where users can save recipes. They can then have many collections of recipes they can refer to. Let’s call each of these collections a recipe box. Also, a recipe will have lots of different ingredients so a user can easily look up what kinds of ingredients they need to make that recipe.
Simple enough!
First, I want to model out how I want the data to be stored. There are a few things to think about when doing this. Let’s use Twitter for example.
| users | |
|---|---|
| id | name |
| 1 | Amy |
| 2 | John |
Let’s pretend this is the users table for Twitter. I’m modeling this out in Rails and it is convention to have a plural table name. We know that a user can have many tweets. How would be a good way to store it? What if we added multiple columns to the users table? Would that be a good way?
| users | ||||
|---|---|---|---|---|
| id | name | tweet_1 | tweet_2 | tweet_3 |
| 1 | Amy | Hello world | Wow another column | Getting kinda crowded |
| 2 | John | What happens if we have hundreds of tweets? | This table will get ridiculously big. | What's a better way to do this? |
As you can see however, this isn’t the best way to do things. Another solution would be to create a separate table for tweets.
| tweets | |
|---|---|
| id | body |
| 1 | Hello world |
| 2 | Much better now |
| 3 | We can just add more rows |
But how can we now associate this tweet table with the users? This is where a join table comes in. We are going to make a user_tweets table that will be our reference for which tweet belongs to which user.
| user_tweets | ||
|---|---|---|
| id | user_id | tweet_id |
| 1 | 1 | 1 |
| 2 | 1 | 3 |
| 3 | 2 | 2 |
In this table, the user_id refers to the id of the user table. The tweet_id refers to the id of the tweet table. These are known as foreign keys because they are referencing a row in a different table. Reading this, we can see that Amy has two tweets - tweet with id 1 and tweet with id 3.
Just below, is a diagram of my ActiveRecord models for the demo API. I used the Rails ERD gem for this.
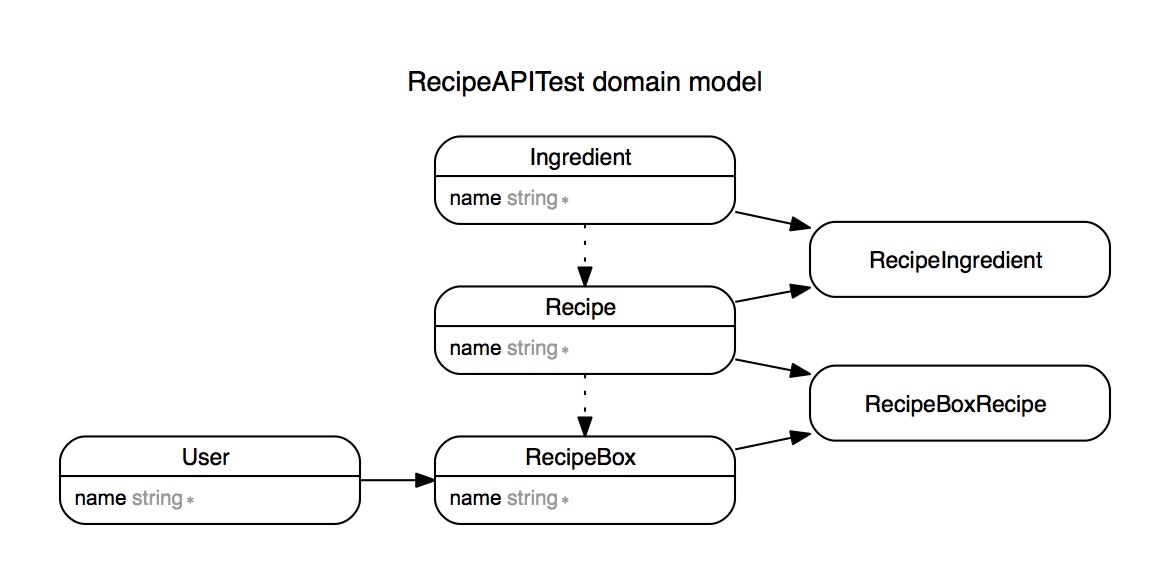
As you can see, a recipe has many ingredients. Likewise, an ingredient will have many recipes. I’ve joined these two tables together through a join table called recipe_ingredients. Just below, you can see how this kind of relationship is defined in your Rails model.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
We use a has_many :through as our model Recipe is matched with the model Ingredient by going through RecipeIngredient. My recipe_ingredients table has a column for both recipe_id and ingredient_id and that is how the two models are connected.
It is a bit of a simpler association between a User and their RecipeBox. A recipe box can only have on user while a user can have many recipe boxes. For this, we will not need a join table. However, a recipe box can contain many recipes and a recipe can also have many recipe boxes. So, we will need a join table for that relation. Here, it is called RecipeBoxRecipe. RecipeBoxRecipe has a recipe_box_id and a recipe_id for its foreign keys.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Now that we have set up these associations, we will be able to call methods like user.recipe_boxes to see all the boxes a chosen user has. We can also choose a specific recipe box and call something like recipe_box.recipes to see all the recipes it contains. Something also interesting to note for Rails is that when we created our tables, we did not have to define which column will be a foreign key. Rails naturally recognizes that the foreign key will be the name of the model with _id added.
ActiveRecord also lets us easily save a row to a table by calling .save on the model.
Let’s say we want to add something to a table.
1 2 3 4 5 | |
Now we have a row that has both a recipe id and ingredient id of 1. Another way to do this is through what is known as mass assignment. This way, we can create this object with a parameter hash instead.
1
| |
Something to think about when using mass assignment are strong parameters. With mass assignment, you can run into the danger where users can modify data they should not be able to.
1 2 3 4 5 | |
This way, the only params that can be modified are the author, title and description.